Střípky z počítačové praxe
Paběrky článků, které jsem sem před lety vkládal. Ponechal jsem jen to, co se snad může ještě někdy hodit…
Pár poznámek
Jak rozsekat textový soubor pomocí delimiteru
Potřebuji občas rozdělit TeXový soubor na samostatné kapitoly. Ručně by to mohlo trvat dost dlouho, používám tedy následující postup (možná ne nejlepší, ale funkční).
Prvně tedy soubor rozdělím, kapitoly mi začínají makrem \nadpis
csplit --digits 2 --quiet --prefix=vystup-part vstupni-soubor.tex "/\nadpis/" "{*}"
První soubor obsahuje hlavičku a další věci před prvním nadpisem, z posledního dám pryč to, co tam přebývá. Hlavičku souboru si nachystám do jednoho souboru, konec do dalšího a cyklem vytvořím nová pdf. Třeba takto:
for i in {01..19}; do cat hlavicka > /tmp/soubor.tex; cat vystup-part$i >> /tmp/soubor.tex; cat paticka >> /tmp/soubor.tex; pdflatex --jobname=clanek-$i /tmp/soubor.tex; done
STM32 a Arduino IDE přes ST-Link
Propojení káblíků je zde: https://leap.tardate.com/arm/stm32f103c8t6/bluepill/usingstlink/
JSON: https://github.com/stm32duino/BoardManagerFiles/raw/main/package_stmicroelectronics_index.json
V upload method ale není ST-link dostupný, použije se STM32CubeProgrammer (SWD).
Je potřeba nainstalovat STM32CubeProgrammer (AUR).
Arduino UNO R4 v Linuxu – nelze nahrát program
Je potřeba přidat udev pravidlo do /etc/udev/rules.d/99-arduino-uno-r4.rules:
# UDEV Rules for Arduino UNO R4 boards
#
# This will allow reflashing with DFU-util without using sudo
#
# This file must be placed in:
#
# /etc/udev/rules.d
#
# After this file is installed, physically unplug and reconnect the device.
#
# Arduino UNO R4
# --------------
#
SUBSYSTEMS=="usb", ATTRS{idVendor}=="2341", ATTRS{idProduct}=="0069", GROUP="plugdev", MODE="0666"
SUBSYSTEMS=="usb", ATTRS{idVendor}=="2341", ATTRS{idProduct}=="0369", GROUP="plugdev", MODE="0666"
#
# If you share your linux system with other users, or just don't like the
# idea of write permission for everybody, you can replace MODE:="0666" with
# OWNER:="yourusername" to create the device owned by you, or with
# GROUP:="somegroupname" and mange access using standard unix groups.
#
Jak zabránit probouzení PC pohybem myši
Použít tento postup, jen je potřeba místo namísto obou enabled zadat disabled.
Správnou identifikaci zařízení si lze předem ověřit přepsáním obsahu souboru /sys/bus/usb/devices/3-8/power/wakeup na disabled.
Windows product key z BIOSu
wmic path SoftwareLicensingService get OA3xOriginalProductKey
# strings /sys/firmware/acpi/tables/MSDM
Reset hesla BIOS na noteboocích Dell (a jiných)
Heslo do BIOSu se standardně resetuje tak, že se kontaktuje servis Dell, který sdělí odemykací kód. Lze to obejít tak, že se kód z odemykací obrazovky zadá sem: bios-pw.org a získaným kódem se heslo do BIOSu zruší.
Instalace KB update z cab souboru
dism /Online /Add-Package /PackagePath:"C:\windows10-kb123456.cab"
Scribus vzdálená odinstalace
- spustit
PowerShelljako správce - připojit se k PC
Enter-PSSession -ComputerName VZDALENEPC - Z adresáře Scribu spustit
.\uninst.exe /S
Deaktivoval se MS Office a nelze ho znovu aktivovat
cmdjako správcecd \Program Files\Microsoft Office\Office16cscript ospp.vbs /dstatus– zobrazí se text, v němž je posledních 5 znaků nainstalovaných licencí (xxxxx)cscript ospp.vbs /unpkey:xxxxx- Po dalším spuštění by mělo být možné Office aktivovat nebo již bude aktivovaný.
Prolomení zámku VBA
- Vytáhnout si soubor
vbaproject.bin, otevřít ho v HEX editoru, vyhledatDPB=a změnit naDPx= - Soubor otevřít, chybovou hlášku ignorovat, nastavit nové heslo a uložit.
Bezpečný výmaz disku HDD
# shred --verbose --random-source=/dev/urandom -n3 --zero /dev/sda
Bezpečný výmaz disku SSD
- Ověříme podporu secure erase:
# hdparm -I /dev/sdX | grep -i erase - Ověříme, jestli není ve stavu frozen:
# hdparm -I /dev/sdX | grep frozen
Pokud vypíše, že je je frozen, pomohlo mi systém uspat a probudit# systemctl suspend - Nastavíme dočasně uživatelské heslo:
# hdparm --user-master u --security-set-pass pass /dev/sdX - A disk smažeme:
# time hdparm --user-master u --security-erase pass /dev/sdX - Pokud tomu nevěříme, můžeme ještě dostupnou část přepsat klasicky nebo zkusit ještě příkaz
# blkdiscard /dev/sdX
Kopírování ACL
# getfacl soubor > soubor-s-ACL # setfacl --set-file=soubor-s-ACL soubor-do-ktereho-prava-kopiruji
Zpětná instalace Win10apps po totální čistce
- Najít si adresu chybějící komponenty ve Store. Nalezenou adresu zadat na stránce store.rg-adguard.net.
- Stáhnout odpovídající soubor s 0 na konci.
Add-AppxPackage -Path "D:\xxxxx.AppxBundle"
Jak nepřejít na Windows 11
Zakázat aktualizaci na Windows 11 se dá například přes GPMC: konfigurace počítače — zásady — nastavení systému Windows — šablony pro správu — součásti systému Windows — Windows Update — Windows Update pro firmy:
- Vybrat cílovou verzi aktualizace funkcí:
povoleno - verze produktu:
Windows 10 - cílová verze:
21H2(případně jiná zvolená)
Pokud už se vám ale začala nová verze stahovat, vidíte ji mezi rozjetými aktualizacemi a nevíte, jak se jí zbavit dříve, než se bude instalovat, podařilo se mi objevit způsob:
- Smazat obsah adresáře
%SystemRoot%\SoftwareDistribution
Nebude to až tak primitivní. Je potřeba to dělat s vypnutým systémem, například z live linuxu. Aby ale šel systémový oddíl připojit, je potřeba řádně Windows vypnout, standardní vypnutí nestačí, takže
shutdown /f /s /t 0. Možná bude potřeba zakázat i hibernaci powercfg /h off
Pár poznámek k Plasmě
Jak překonat klacky pod nohama — zábavy není nikdy dost, takže jsem přece jen i v roce 2021 sednul a píšu si sem pár poznámek.
Plasma 5.21
V Plasmě 5.21 se změnila „nabídka start“, tedy Kickoff, z mého pohledu nepoužitelným směrem. Starší verze se dá vrátit pomocí widgetu Legacy Kickoff, který se dá stáhnout standardně přes nabídku přidání widgetu.
Stejně tak se v Plasmě 5.21 změnil dialog pro připojení externího média. Namísto původně nabízeného tlačítka pro připojení je tam nyní tlačítko Připojit a otevřít (aby se ušetřila práce těm, kteří si připojený disk procházejí v Dolphinu). Jenže ti, kteří Dolphin nepoužívají, z toho mají nyní opruz… Jedinou cestou je překompilovat balíček plasma-workspace, ve kterém vrátíme změny souboru applets/devicenotifier/package/contents/ui/DeviceItem.qml.
Tady mám připravený diff soubor, v Archu pak ještě do PKGBUILD přidáme sekci prepare
prepare() {
cd "${srcdir}"/$pkgname-$pkgver
patch -Np0 -i "${srcdir}"/DeviceItem.diff
}
Při používání Waylandu mi v Plasmě nefungovala mrtvá klávesa pro háčky a čárky. Vyřešit to lze instalací balíčku ibus a editací souboru /etc/environment, kam je potřeba doplnit následující kód:
INPUT_METHOD=ibus GTK_IM_MODULE=ibus QT_IM_MODULE=ibus XMODIFIERS=@im=ibus
Fotografování, úprava obrázků
Záležitosti, které se mohou hodit při zpracování obrázků v počítači.
Zarovnání sady různě exponovaných fotek
Občas se hodí vyfotit objekt při různých expozicích (například kvůli moc velkému kontrastu) nebo to člověk potřebuje, protože je HDR maniak. Foťáky to většinou umějí, lze nastavit nasnímání série fotek při automatické změně expozice. Ideální je použít kvalitní stativ. Pokud fotky nasnímáte bez stativu, bývá potom složité je na sebe přesně zarovnat. Ale vlastně to složité vůbec není. Hugin totiž obsahuje šikovný prográmek:
$ align_image_stack -a predpona-pro-nazev-zarovnanych-souboru snimek-1.tif snimek-2.tif snimek-3.tif
Za parametr -a se napíše předpona pro nové soubory a pak se jen doplní sada fotek, které mají být zarovnány (stačí klidně jen *.tif, pokud to mají být všechny tiffy v adresáři.
Také jsem se ještě dočetl, že s pomocí parametru --ContrastWindowSize=n, kde n dáme hodnotu 7 nebo 9, můžeme na úkor delšího času dostat kvalitnější výsledky. A pro zarovnání rozdílně zvětšených snímků slouží parametr -m
Rychlý převod RAW fotek do JPG
Fotím zásadně do raw. Což samozřejmě má své naprosto jasné důvody, ovšem nese to s sebou časový problém s prohlížením obrázků (pokud nemáte, či neexistuje nějaký rychlý prohlížeč). Takže to u nás doma vždy vypadalo tak, že jsme odněkud přišli a já seděl a převáděl a převáděl… A dostával vyčteno, že to trvá děsně dlouho, než si ostatní mohou fotky prohlédnout. Evidentně to není jen můj problém, většina těch, kdo fotí do jpegu, to zdůvodňuje tím, že nemá čas či zájem sedět hodiny nad fotkami a upravovat je. Ale přitom by každý určitě uvítal mít možnost vybrané fotky doladit. Řešení mne napadlo, i když docela pozdě (nikdy není pozdě), až když se kdosi ptal na možnost převést raw bez interpolace, a někdo jiný ho nasměroval na autora dcraw. Tehdy jsem kouknul na dcraw, že sám o sobě danou věc umí, ale především mne napadlo, že jsem pitomec, když jsem ho už dávno nevyužíval pro hromadný automatický převod fotek.
Nakecal jsem se už dost, zde je řešení:
#!/bin/bash for i in *.x3f do dcraw -w -c $i | convert -quality 97 - `basename $i .x3f`.jpg done
Jak jednoduché a prosté :-) Samozřejmě to lze aplikovat na všechny podporované raw formáty, takže pokud máte třeba Nikon, zaměníte x3f za NEF. A už nemusíte prznit fotky focením do jpegu.
Prolínání naštosované sady fotek
Před nějakou dobou jsem si zde napsal poznámku, jak v rámci možností zarovnat štos fotek. Dnes bych doplnil o pár možností následného zpracování.
Enfuse
V Linuxových distribucích asi nejpoužívanější program k tomuto účelu.
Zde je příklad, jak s jeho pomocí vytvořit obrázek ze štosu fotek snímaných za účelem vysoké hloubky ostrosti – snímání identické scény s posuvem roviny ostrosti tak, aby byla pokryta celá oblast, která má být ostrá.
$ enfuse -o vystupni-soubor.tif --exposure-weight=0 --saturation-weight=0 --contrast-weight=1 --hard-mask <seznam vstupních souborů>
--exposure-weight– váha expozice. Hodnotu 1 by dostala v případě, že bychom chtěli dělat expoziční prolínání.--saturation-weight– váha nasycení. Hodnotu až 1 by dostala, pokud bychom chtěli vybírat sytější barvy. V našem případě nemá smysl.--contrast-weight– váha kontrastu. To je to, podle čeho určujeme, jelikož ostrost se určuje právě podle velikosti lokálního kontrastu.
Další informace k tomuto programu jsou na wiki stránkách projektu.
TuFuse
Když jsem výše zmiňoval expoziční prolínání, tak jsem se ohledně něj v nějaké diskuzi dočetl, že lepší výsledky dává (Windows only) program TuFuse. Je to program pro příkazovou řádku a spolehlivě pracuje i prostřednictvím WINE. Otestoval jsem ho při spojení fotek jeskyně Jáchymka a fungoval opravdu hezky. Na odkazovaných stránkách projektu jsou popsány použitelné parametry včetně několika příkladů.
K tomuto programu jsem našel ještě velmi zajímavou wikistránku popisující skript využívaný přímo z prohlížeče obrázků gQview.
Twibright Registrator
Další program z této skupiny nástrojů, prezentuje se jako program pro redukci šumu a zlepšení rozlišení, naleznete ho na stránkách Twibright Labs.
Kompilace je velmi snadná a rychlá, stačí jeden příkaz make a za pár vteřin je hotovo.
Nic moc jsem s ním zatím nedělal, takže opět vizte stránku projektu, jsou tam popsány parametry i příklady.
Immix
Tak jsem u dalšího prolínače. Stránky projektu jsou na adrese immix.sf.net, a jsou přehledné.
Program má tentokrát jednoduché GUI. Trochu nepříjemné jsou omezené vstupní formáty, ale vzhledem k tomu, že se prezentuje jako odšumovač pro podexponované záběry při vysokém ISO, jehož využití předpokládám převážně u jpeg fotek z kompaktu, nelze mu to mít za zlé. Každopádně umí i png, takže jde použít i pro kvalitnější snímky.
CombineZP
V diskuzi na Paladixu jsem se dočetl o (Windows only) programu CombineZP, který by měl sloužit ke stejnému účelu, jako první popsaný skript – zvýšení hloubky ostrosti. Zatím jsem ho nezkoušel, možná někdy…
Hromadné otočení fotek dle EXIF
V digiKamu mám spoustu fotek, které mají svou rotaci pouze definovánu v EXIF, ale reálně jsou naležato. Není to problém až do okamžiku, kdy je chci vypálit někomu jinému. Mnohé prohlížeče ve Windows s touto eventualitou nepočítají a převracet správně fotky neumějí. Pak je pěkné tuto práci udělat za ně. Stačí na to jednoduchý příkaz v adresáři s vybranými fotkami:
$ for i in *.jpg; do jhead -autorot $i; done
Odstranění chromatické aberace
Jednoduchý návod, jak odstranit chromatickou aberaci, i když nemusí vždy fungovat stoprocentně. Budeme k tomu potřebovat mít nainstalovaný program Hugin.
Pro zjištění potřebných parametrů použijeme příkaz tca_correct:
$ tca_correct -o abcv fotka-s-aberaci.tif
Po chvíli to na nás vychrlí spoustu informací, přičemž na úplně posledním řádku budou potřebné parametry. Bude to vypadat například takto:
-r 0.0000438:0.0002644:-0.0003223:1.0003769 -b -0.0007529:0.0011753:0.0001412:1.0001999
tenhle řádek zkopírujeme a použijeme jako parametr pro program fulla následujícím způsobem:
$ fulla -r 0.0000438:0.0002644:-0.0003223:1.0003769 -b -0.0007529:0.0011753:0.0001412:1.0001999 fotka-s-aberaci.tif
Po krátké chvíli nám program vygeneruje soubor fotka-s-aberaci_corr.tif, který by měl mít aberaci odstraněnou. Pokud nám kvalita nepostačuje, je nutno použít postup složitější, který je popsán na stejné stránce, odkud jsem čerpal tento návod.
Dávkový převod SVG na PNG
Nějakou dobu jsem měl zablokován update knihovny librsvg na verzi >=2.14, protože špatně zobrauje určité SVG soubory. Především mi to vadilo, že to mršilo mé jediné oblíbené eXperience Crystal ikonky. Jenže postupně přibývaly programy, které novou verzi této knihovny vyžadovaly, takže jsem se rozhodnul problematickou část ikon převést do png. Ručně bych z toho asi umřel, takže jsem se to snažil vyřešit jinak, až jsem našel řešení v příkazovém řádku:-)
for i in *.svg do inkscape -f "$i" -e "$i.png" -w 48; done
Tento příkaz spustíte v adresáři s SVG soubory. Za parametrem -e zadáte cestu k vytvořeným PNG. Parametr -w určuje šířku v pixelech. Samozřejmě musíte mít nainstalován program InkScape. A samozřejmě to můžete použít i na jiné formáty, které InkScape podporuje.
Jak otevřít soubory Corel DRAW!
Již mnohokrát jsem potřeboval otevřít soubory, které plodí vektorový program Corel DRAW! Vždy jsem to řešil tak, že jsem si dotyčný soubor vzal do práce a tam si ho otevřel v Corelu a uložil třeba do AI nebo SVG. Dnes jsem ovšem čirou náhodou objevil skvělý konvertor, pomocí něhož lze otevírat soubory v Linuxu, navíc přímo z Inkscape…
Jedná se o UniConvertor

Sazba a PDF
Drobnosti k práci s PDF
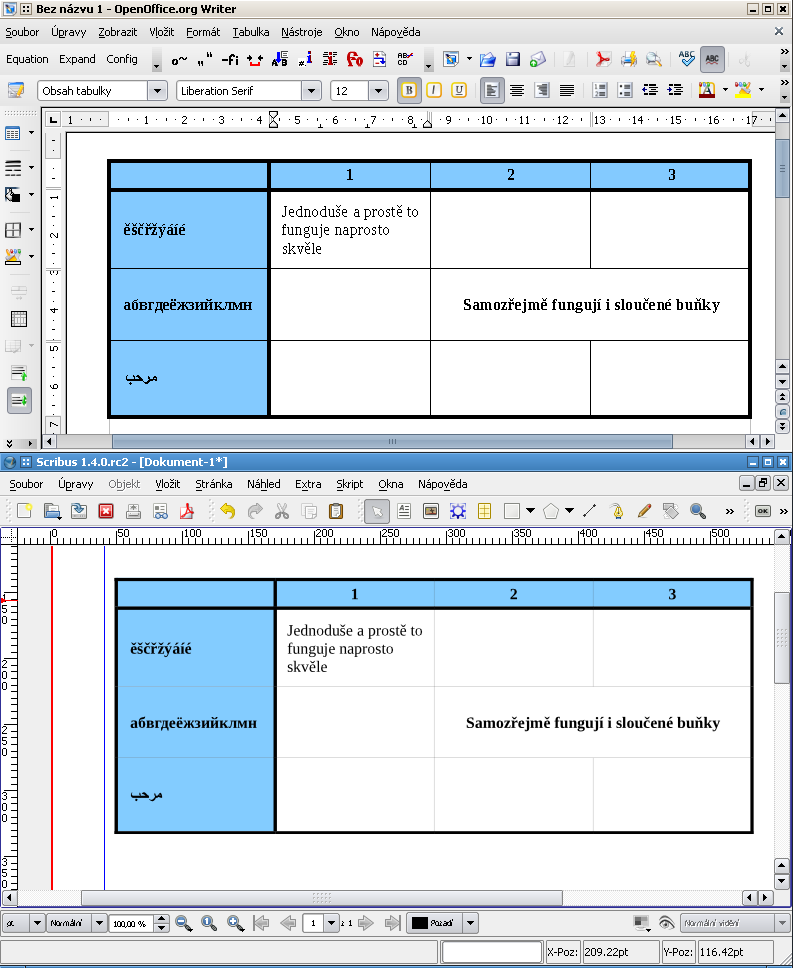
Scribus – vložení tabulky z Writeru
Objevil jsem způsob, jak vložit tabulku vytvořenou v OOo Writeru do Scribu při zachování kompletního formátování a národních znaků (funguje diakritika, azbuka i jiné abecedy).
- vytvoříme tabulku ve Writeru
- soubor exportujeme jako PDF
- PDF převedeme příkazem
pdftopsz balíku poppler na postscript - postscriptový soubor převedeme příkazem
ps2epsz balíku texlive na encapsulated postscript - výsledný eps naimportujeme do Scribu a je hotovo
Elegantní čtenářský deník pohodlně v LaTeXu
Tomáš potřeboval do školy vést čtenářský deník. Vzhledem k tomu, co plihnil v OpenOffice.org, jsem se rozhodnul udělat mu nějakou šablonu pro LaTeX, kde nebude mít možnost dělat úžasné prasárny, ale bude se moci soustředit na psaní obsahu.
Přece jen se v LaTeXu tak moc nevyznám, takže jsem si nechal to nejdůležitější poradit, a pak jsem to uhladil do úhledného kabátku.
Takže celé to mám rozděleno do samostatných souborů kvůli přehlednosti:denik-cs.cls– třída dokumentudenik.tex– kostra dokumentuknihy.tex– vkládaný seznam dokumentů s jednotlivými knihami, lze generovat automaticky skriptem, nebo sepsat ručněcelni-strana.pdf– pro titulní stranu mám vytvořené rádoby nádherné samostatné jednostránkové pdf- jakkoliv nazvaný skript (vypsaný níže), který doplní pomocí programu
vlnanedělitelné mezery, vygeneruje seznam knih a vytvoří výsledný pdf soubor - podadresář
knihy– obsahuje soubory s jednotlivými články - podadresář
covers– obsahuje obrázky s titulními stranami knih
Základem deníku je třída denik-cs:
%obsah souboru denik-cs.cls \ProvidesClass{denik-cs} \usepackage{wrapfig} \usepackage{graphicx} \usepackage{pdfpages} % Velikost papíru a standardní velikost písma \LoadClass[12pt,a4paper]{article} %pro oboustranný tisk přidat parametr twoside \usepackage[T1]{fontenc} \usepackage[utf8]{inputenc} \usepackage[czech]{babel} \usepackage{palatino} %volba fontu, možno zkusit avant, bookman, newcent, palatino, helvet, times % Nastavení okrajů stránky \usepackage[top=2cm,bottom=2cm,left=2cm,right=2cm]{geometry} % Definice příkazů používaných v knize \newcommand\obalknihy[1]{\begin{wrapfigure}{r}{130pt} \setlength\fboxsep{5pt} \setlength\fboxrule{0.5pt} \fbox{\includegraphics[width=115pt]{covers/{#1}}} \end{wrapfigure}} %obrázek přebalu knížky s rámečkem \def\kniha#1{\newpage{}\section*{\sffamily\Large\bfseries#1~~\leaders\vrule height 5pt depth -4.5pt \hfill \null} \addcontentsline{toc}{section}{#1}} \def\autor#1{\par\removelastskip\vskip\smallskipamount\noindent \textit{#1}\par \nobreak\vspace{3em}\@afterheading} \def\mininadpis#1{\par\removelastskip\vskip\medskipamount\noindent \textbf{#1}\par \nobreak\@afterheading} \def\obsah{\mininadpis{Obsah knihy}} \def\hodnoceni{\mininadpis{Můj názor}} \def\ukazka{\mininadpis{Ukázka z knihy}} \def\citace#1{\begin{quote}\emph{#1}\end{quote}} % Úprava obsahu, aby v něm byly vodicí tečky \makeatletter \renewcommand\l@section[2]{% \ifnum \c@tocdepth >\z@ \addpenalty\@secpenalty \addvspace{1.0em \@plus\p@}% \setlength\@tempdima{1.5em}% \begingroup \parindent \z@ \rightskip \@pnumwidth \parfillskip -\@pnumwidth \leavevmode %\bfseries \advance\leftskip\@tempdima \hskip -\leftskip #1\nobreak\ \leaders\hbox{$\m@th\mkern \@dotsep mu\hbox{.}\mkern \@dotsep mu$} \hfil \nobreak\hb@xt@\@pnumwidth{\hss #2}\par \endgroup \fi} \makeatother
A základní kostra dokumentu je v souboru denik.tex:
% obsah souboru denik.tex \documentclass{denik-cs} \begin{document} \pagestyle{empty} % vypne číslování stránek \includepdf{celni-strana.pdf} % vloží úvodní stránku \newpage \tableofcontents \newpage \pagestyle{plain} % zapne obyčejné číslování \setcounter{page}{1} % nastaví čítač stránek znovu od jedné %-----<<< kapitoly >>>----- \input{knihy.tex} %vloží seznam souborů \end{document}
Seznam vkládaných souborů s obsahy jednotlivých knih jsem vytáhnul do samostatného souboru knihy.tex a generuji ho pomocí skriptu, ale lze samozřejmě napsat i ručně. Vypadá nějak takto:
% obsah souboru knihy.tex \input{knihy/capek-krakatit.tex} \input{knihy/capek-RUR.tex} \input{knihy/nix-01-sabriel.tex} \input{knihy/nix-02-lirael.tex} \input{knihy/pullman-01-svetla-severu.tex} \input{knihy/pullman-02-jantarove-kukatko.tex} \input{knihy/pullman-03-dokonaly-nuz.tex} \input{knihy/king-stephen-nezbytne-veci.tex}
No a ještě bash skript, který udělá tu nudnou práci:
#!/bin/bash cd ./knihy for i in *.tex; do vlna -v KkSsVvZzOoUuAI $i; done rm *~ cd .. for kniha in knihy/*.tex; do echo "\\input{$kniha}"; done >knihy.tex pdflatex denik.tex pdflatex denik.tex rm denik.aux rm denik.log rm *~ acroread denik.pdf
Tak. A na vášnivém čtenáři pak zbývá jen psát obsahy knih bez toho, že by řešil formátování. Soubor, který napíše a umístí do podadresáře knihy, bude obsahovat něco takového:
\kniha{Nezbytné věci} \autor{Stephen King} Co to tam může být? Co je to za divný název \uv{Nezbytné věci}? Obchodník ví své, ví, jak funguje lidské myšlení. Pozoruje ho už tisíce let. Pronikne až do vaší mysli, zjistí, po čem ve skrytu duše opravdu, přímo nezbytně toužíte, a pak vám to nabídne. Za cenu, které se nedá odolat\dots \obalknihy{nezbytne-veci.jpg} \obsah Do městečka Castle Rock přijíždí podivný obchodník Leland Gaunt… Jeho prvním zákazníkem je jedenáctiletý Brian Rudko, který jede náhodou kolem ještě před oficiálním otevřením… \hodnoceni Román Nezbytné věci je o boji dobra se zlem, zpodobněným záhadným obchodníkem, který vám prodá přesně to, po čem toužíte\dots{} Kniha je velmi čtivá, ale pokud máte paměť děravou jako já, doporučuji vám, abyste si dělali poznámky, kdo je kdo, jinak se v množství postav budete ztrácet.
A ještě ke stažení na ukázku jeden ukázkový soubor s knihou a PDF výsledek v ořezané formě bez titulní strany s tímto jedním souborem
Sloučení více PDF do jednoho
Na tuhle činnost lze sice použít velmi snadno convert z balíku ImageMagick, ale může se vám při tom stát, že budete mít výsledné PDF narastrováno. Mnohem spolehlivější je použít GhostScript:
gs -dNOPAUSE -sDEVICE=pdfwrite -sOUTPUTFILE=vysledny-soubor.pdf -dBATCH vstupni-soubor-1.pdf vstupni-soubor-2.pdf vstupni-soubor-dalsi-a-dalsi.pdf
Sazba knihy 2×A5 —> A4
Snažil jsem se z některých programů dostat ven brožuru a zjistil jsem, že se nejedná o běžně podporovanou záležitost. Dokonce ani Adobe InDesign ve verzi 2 to ještě neumí. Takže jsem hledal způsob náhradní. Dokument exportovat do postscriptu po jednotlivých stránkách a vazbu vytvořit až poté.
Skript:
#!/bin/bash psbook $1 | psnup -pA4 -PA5 -s1 -2 >/tmp/book.ps psselect -o /tmp/book.ps>/tmp/book1.ps psselect -e /tmp/book.ps>/tmp/book2.ps ps2pdf /tmp/book1.ps $1.1.pdf ps2pdf /tmp/book2.ps $1.2.pdf
- Příkaz
psbookdokument přestránkuje tak, aby pořadí odpovídalo brožuře - Příkaz
psnupnaskládá stránky A5 vedle sebe na stránky A4 - Pomocí
psselectto rozdělíme na sudé a liché pro oboustranný tisk (pokud nemáme duplexní jednotku) - Příkazem
ps2pdfz toho stvoříme PDF soubory
Aby to nebylo tak jednoduché, lezlo mi výsledné PDF trošku ořezané. K tomu bylo potřeba editovat soubor gs_init.ps (součást balíčku ghostscript, v mém případě se nacházel v adresáři /usr/share/ghostscript/8.70/Resource/Init/). Bylo potřeba odkomentovat řádek
% /DEFAULTPAPERSIZE (a4) def– jinak totiž lezl výsledek na formátu
letter
No, a aby to nebylo tak pěkné a jednoduché, tak jsem nakonec zjistil, že tohle sice pěkně funguje například se soubory z programů Scribus či LaTeX, ale z InDesignového postscriptového souboru to udělá paskvil. Součástí psutils jsou skripty pro opravu ps souborů z několika programů, ale zrovna InDesign mezi nimi není :-/
Takže nakonec to vypadá takto (z InDesignu se exportují přímo PDF soubory):
#!/bin/bash echo "======================================================" echo "Použití:" echo "\$ book zdrojový_soubor_A5.pdf název_cíle_bez_přípony [r]" echo "r - parametr pro ruční duplex" echo "======================================================" echo " " pdftops $1 /tmp/book.a.ps psbook /tmp/book.a.ps | psnup -pA4 -PA5 -s1 -2 >/tmp/book.ps case $3 in r) psselect -o /tmp/book.ps>/tmp/book.1.ps;psselect -e /tmp/book.ps>/tmp/book.2.ps;ps2pdf /tmp/book.1.ps $2.1.pdf;ps2pdf /tmp/book.2.ps $2.2.pdf;; *) ps2pdf -dPDFSETTINGS=/prepress /tmp/book.ps $2.pdf;; esac rm /tmp/book.*
Pokud vynecháte v příkazu ps2pdf parametr -dPDFSETTINGS=/prepress, dostanete ve výsledném dokumentu o něco nižší kvalitu obrázků, na čemž můžete ušetřit hodně datového objemu a pro některé případy to nemusí vadit.
A ještě rada na konec: důvěřuj, ale prověřuj! Stalo se mi, že pdftops narastroval první stránku dokumentu, čímž ji totálně degradoval, takže doporučuji kontrolu výsledku.
Převod A4 postscriptu na PDF pomocí ps2pdf
Některé utilitky fungují sice perfektně, ale přsto bývá někdy výsledek jiný, než by člověk čekal a k tomu se správný postup nedočte ani v manuálové stránce. Jako například, když je potřeba převést postscript na PDF o veliskoti strany A4. Takže takhle:
$ ps2pdf -sPAPERSIZE=a4 -dOptimize=true -dEmbedAllFonts=true vstupni-soubor.ps
Zálohování
Inkrementální zálohování dat
…s možností obnovy starší verze, či smazaných souborů
Tak se mi v práci konečně poštěstilo koupit pořádný externí disk, takže mi spadnul obrovský kámen ze srdce, způsobený velkým problémem nějak zálohovat data. RAID sice dokáže pomoci, když se podělá HW, ale za ta léta jsou poznal, že SCSI disky jsou mnohem spolehlivější, než uživatelé, kteří k datům mají přístup. Ale zálohovací disk nás ochrání i před nimi ;-)
Zálohuji několik adresářů a používám k tomu program rdiff-backup. A zde uvedený skript, který spouštím 1× týdně pomocí cronu.
#!/bin/bash zalohuj () { echo "============ Zaloha adresare adresar1 =================" echo "Pripojuji disk" mount.cifs //192.168.0.56/adresar1 /mnt/adresar1 -ouser=root,pass=xxxxxxxx,iocharset=utf8 echo "Zalohuji..." find /mnt/adresar1 | grep -E -i -f /root/zalohovani/seznam.txt | rdiff-backup --include-filelist-stdin --exclude '**' /mnt/adresar1 /mnt/backupdisk/adresar1 echo "Zaloha adresare adresar1 dokoncena, odpojuji disk" echo " " umount.cifs /mnt/adresar1 for adresar in adresar2 adresar3 adresar4 adresar5 do echo "============ Zaloha adresare $adresar =================" echo "Pripojuji disk" mount.cifs //192.168.0.56/$adresar /mnt/$adresar -ouser=root,pass=xxxxxxxx,iocharset=utf8 echo "Zalohuji..." rdiff-backup /mnt/$adresar /mnt/backupdisk/$adresar echo "Zaloha adresare $adresar dokoncena, odpojuji disk" echo " " umount.cifs /mnt/$adresar done echo "Zaloha `date` probehla v poradku" >> /root/zalohovani/zaznam for adresar in adresar1 adresar2 adresar5 do echo "================== $adresar =================" >> /root/zalohovani/zmeny rdiff-backup --list-changed-since 1W /mnt/backupdisk/$adresar >> /root/zalohovani/zmeny done echo "================== místo na discích =================" >> /root/zalohovani/zmeny df -Th >> /root/zalohovani/zmeny umount /mnt/backupdisk } echo "Změny k `date`:" > /root/zalohovani/zmeny if mount -Lzaloha /mnt/backupdisk 2>/dev/null then zalohuj else echo "ERROR: Zaloha `date` se nezdarila" >> /root/zalohovani/zaznam fi mail -s "Probehlo zalohovani" ota@xxx.cz < /root/zalohovani/zaznam mail -s "Probehlo zalohovani - seznam zmen" ota@xxx.cz < /root/zalohovani/zmeny exit 0
Předpokladem úspěchu je, že na záložním disku i v adresáři /mnt na systémovém disku mám vytvořeny adresáře, které jsou pojmenovány stejně, jako se jmenují sdílení na serveru, odkud jsou zálohy prováděny. Pokud nechcete využívat cyklus for .. in, můžete si pojmenovat co chcete, jak chcete. Nejdůležitější je příkaz rdiff-backup /co/zálohuji /kam/zálohuji.
- Vyčistím si soubor
zmenytím, že ho přepíšu řádkem se dnem zálohy - Do adresáře
/mnt/backupdiskse pokusím připojit externí disk. Pokud se to podaří, spustím zálohu, pokud ne, zapíšu do záznamu chybovou hlášku - Odešlu si soubor se záznamem (v němž mám seznam všech dní, kdy se skript spustil a jeho úspěšnost) a soubor se změnami, které byly během zálohy provedeny
zalohuj () a dělá tohle:
- Připojí přes sambu síťový disk do určeného adresáře v
/mnt/ - Pomocí
rdiff-backupudělá jeho zálohu - Odpojí ho. Uvedený cyklus provede se všemi zálohovanými adresáři
- Do záznamu zapíše, že vše proběhlo v pořádku
- Do souboru se změnami vygeneruje, co vše se změnilo v adresářích, u kterých mne to zajímá (šlo by to dělat v pohodě v rámci toho prvního cyklu, ale to je jedno). Takovýto soubor mi potom může pomoci mnohem snadněji najít, kdy byl některý soubor smazán a jak se jmenoval.
- Na konec souboru se změnami připíše, kolik mám na discích místa
- Odpojí externí disk
Ve skriptu je vidět, že adresář1 zálohuji jinak, než ostatní. Z něj totiž zálohuji jen vybané soubory, uvedené v souboru seznam.txt. Je to ochrana před tím, abych neměl zálohovací disk zaliskaný nějakými hloupými videi, či mp3. Ostatní adresáře zálohuji kompletně. Inspiraci jsem načerpal v tomto seriálu na linuxsoft.cz, kde najdete i to, jak má vypadat soubor seznam.txt
Zálohování dat

Data se dají zálohovat různě. Pokud je jich málo, je způsobů hodně. Pokud je jich moc, už jsou s tím problémy. Já mám na zálohy koupený samostatný disk, který si leží v klidu a chládku ve špajzce. Sem tam ho strčím do šuplíku a zálohuji data pomocí rsync:
rsync -avz /co/se/bude/kopírovat /kam/se/bude/kopírovat
Co se jinam nevešlo
Jednoduchý firewall pro desktop
netfilter, čili iptables
Tak jsem se konečně doma rozhoupal k tomu, abych namísto prostého TCP wrapperu začal používat iptables. Měl jsem dost dlouho problém pochopit, že je to opravdu jednodušší, než to vypadá (alespoň to, co stačí na zmíněném desktopu)
Uvedený firewall je opravdu jednoduchý, asi není dokonalý, ale věřím, že by svou úlohu měl plnit.
# takže jako výchozí nastavím zakázání všeho, # co se snaží ke mně a přeze mne dostat (výchozí hodnoty, aplikované na # všechny pakety, které nesplní žádnou podmínku) # Odchozí provoz nijak omezovat nebudu - sám sebe omezovat nemusím iptables -P INPUT DROP iptables -P FORWARD DROP # povolím loopback iptables -A INPUT -i lo -j ACCEPT # povolím příjem všeho, o co jsem si požádal iptables -A INPUT -i eth0 -m state --state RELATED,ESTABLISHED -j ACCEPT # povolím icmp pakety, ale jen přiměřeně, # kdyby se mne někdo snažil upingat k smrti iptables -A INPUT -i eth0 -p icmp -m limit --limit 3/sec --limit-burst 5 -j ACCEPT # slušně odmítnu požadavek (např. FTP serveru) na auth iptables -A INPUT -i eth0 -p tcp --dport auth -j REJECT # povolím igmp multicast protokol iptables -A INPUT -i eth0 -p igmp -j ACCEPT # nakonec ještě povolím tcp i udp porty pro DC++ # (potřeba nastavit si svoje) iptables -A INPUT -i eth0 -p tcp -m tcp --dport 23456 -j ACCEPT iptables -A INPUT -i eth0 -p udp -m udp --dport 23456 -j ACCEPT # případně, pokud jste z nějakého důvodu paranoidní # můžete se omezit třeba jen na určitou síť (obvykle metropolitní), třeba takto: iptables -A INPUT -i eth0 -p tcp -m tcp --dport 23456 -s 111.222.0.0/19 -j ACCEPT iptables -A INPUT -i eth0 -p udp -m udp --dport 23456 -s 111.222.0.0/19 -j ACCEPT iptables -A INPUT -i eth0 -p tcp -m tcp --dport 23456 -s 10.0.0.0/16 -j ACCEPT iptables -A INPUT -i eth0 -p udp -m udp --dport 23456 -s 10.0.0.0/16 -j ACCEPT # V nějaké podobné síti jsem já, jsou tam uživatelé s veřejnými adresami # - to je ta síť, zde uvedená jako 111.222.0.0/19, a s privátními adresami # přidělovanými v rozsahu sítě 10.0.0.0/16 # V jaké síti se nalézáte, vám prozradí např. příkaz whois # (samozřejmě je potom potřeba vynechat ty řádky, které jsou o odstavec výše ;-))
V mnou používaném Arch Linuxu jsem si následně příkazem iptables-save > /etc/iptables/iptables.rules pravidla uložil do zmíněného souboru. O načtení při startu se pak postará daemon iptables, spouštěný pomocí /etc/rc.conf ještě před daemonem network. Tohle se samozřejmě v jednotlivých distrech liší.
Rekurzivní změna oprávnění k adresářům
Občas potřebuji nastavit stejná práva na celý adresářový strom. Jasně: chmod -R bla bla bla. Jenže problém je v tom, že na souborech obvykle nechci mít atribut spustitelný, kdežto na adresářích být musí. Takže první nastavím na celý strom práva bez spustitelného atributu, a potom opravím práva na adresářích:
find /cesta/k/vrchnimu/adresari -type d -exec chmod 750 {} \;
Hezký příkaz, že? :-)
Odkazy z Firefoxu a Thunderbirdu
V některých distribucích můžete narazit na problém, že nefungují odkazy z Firefoxu a Thunderbirdu. Řešení je snadné.
Firefox mailto://
Otevřete si soubor ~/.mozilla/firefox/xxxxxx.default/prefs.js a přidáte nebo upravíte tento řádek:
user_pref("network.protocol-handler.app.mailto", "/usr/bin/thunderbird");
Odkazy z Thunderbirdu
Otevřete si soubor ~/.thunderbird/xxxxxx.default/prefs.js a přidáte nebo upravíte tyto řádky:
user_pref("network.protocol-handler.app.ftp", "firefox");
user_pref("network.protocol-handler.app.http", "firefox");
user_pref("network.protocol-handler.app.https", "firefox");
Thunderbird 3
Nějaký pátek už tu máme Thunderbird 3, ve kterém opět přestaly fungovat odkazy. Řešení je tentokráte plně klikací:
Edit --> Preferences --> Advanced --> tlačítko Config Editor- Najít a změnit následující 3 hodnoty na
true:network.protocol-handler.warn-external.ftp default boolean false network.protocol-handler.warn-external.http default boolean false network.protocol-handler.warn-external.https default boolean false
- Uzavřít Config Editor
- Opět do menu:
Tools --> Add-ons --> odkaz Browse all Add-ons. Tím se spustí okno 'Launch Application', kde si každý zvolí svůj oblíbený prohlížeč. - Pokud by to kliknutí náhodou nefungovalo, mělo by pomoci zadat plnou cestu k prohlížeči v tomto klíči:
network.protocol-handler.app.http
Truecrypt – hidden volume
Truecrypt – dokonalý nástroj pro tvorbu zašifrovaných disků. Data můžete uložit do souboru, nebo třeba i do nenaformátovaného diskového oddílu. A to není všechno. Umí i takovou srandu, že si oddíl se skutečně chráněnými daty schováte do oddílu, kam nastražíte jiná data, jejichž vyzrazení vám nezpůsobí pupínky, a v případě, že budete donuceni prozradit heslo, prozradíte heslo právě pro tato data. Skrytá data zůstanou naprosto neviditelná, neprozradí vás ani velikost oddílu, protože se program chová, jako by nic schovaného uvnitř neexistovalo. (To je blbá věta, co? Chápaví snad pochopili :-))
Přestože již nějaký ten pátek existuje pátá řada tohoto programu, utekl jsem od ní velmi rychle zpět k verzi 4.3a, jejíž ovladač funguje jako jaderný modul. Verze 5.0 měla nějaké nepříjemné chybky, navíc používá fuse, prostě mi nevyhovuje. A GUI opravdu nepotřebuji. Takže se následující návod verze 5.x netýká (i když to asi bude podobné, navíc to v ní můžete naklikat – i když nezkoušel jsem to).
Vytvoříme vnější svazek (outer volume) na
/dev/sdb2:truecrypt --filesystem none --type normal -c /dev/sdb2
Namapujeme svazek, ale nepřipojíme ho:
truecrypt /dev/sdb2
A naformátujeme:
mkfs.ext2 /dev/mapper/truecrypt0
Odpojíme svazek:
truecrypt -d /dev/sdb2
Vytvoříme uvnitř skrytý svazek (hidden volume):
truecrypt --filesystem none --type hidden --size 1500M -c /dev/sdb2
Tento skrytý svazek namapujeme, ale nepřipojíme:
truecrypt /dev/sdb2 (použijeme heslo pro skrytý svazek)
A skrytý svazek naformátujeme:
mkfs.xfs /dev/mapper/truecrypt0
Opět ho odpojíme:
truecrypt -d /dev/sdb2
Připojíme vnější svazek se zapnutou ochranou skrytého svazku:
truecrypt -P /dev/sdb2 /mnt/tc
- Nakopírujeme tam nějaká „jakožetajná” data
Opět ho odpojíme:
truecrypt -d /dev/sdb2
Teď už můžeme vesele připojovat. Který svazek se připojí, se určí pomocí použitého hesla. Nikdy nezapisujte do vnějšího svazku, pokud jste nepoužili parametr
-Ppro ochranu svazku skrytého. Připojení vnějšího svazku bez ochrany slouží pouze pro krizové situace, kdy jste donuceni vyzradit své heslo:truecrypt /dev/sdb1 /mnt/tc